

之前写过一个在Intel Devcloud上使用llama.cpp执行大型语言模型推理的文章,最近一段时间一直在测试利用各种方式量化,执行LLM推理。在搜索使用英特尔XPU(ARC系列独显/数据中心系列加速卡)来加速大型语言模型推理时发现了英特尔推进的一个项目,针对英特尔至强,酷睿等支持AVX512指令集进行优化的执行大型语言模型推理的工具。

英特尔家的东西还是比特殊,比方说XPU,用的人就非常少,或者说鲜有人拿着来加速AI推理或微调的,目前比较火的Pytorch框架也是不支持XPU的。所以英特尔自己针对自己的硬件开发了很多工具,来提供相应的硬件加速方案。经过测试,在XPU上使用英特尔开发的BIGDL运行大模型推理速度是要优于使用llama.cpp的opencl将负载转移到XPU的。
由于用的少,开发人员也少,英特尔经常亲自下场给这些开源项目贡献代码,截至本文章编写的时候,英特尔以及在积极推进给llama.cpp增加intel-extension-for-transformers的针对CPU的优化以及通过SYCL对英特尔XPU/iGPU提供直接支持。
不过考虑到相关的代码合并进llama.cpp可能还需要一些时间,所以就把这篇文章发出来了。ITREX(intel-extension-for-transformers)是英特尔在GITHUB上的一个开源项目,提供类似于TransformersAPI,用于直接加载HuggingFace上模型的方案。并且支持在Intel Xeon Scalable Processors|Intel Xeon CPU Max Series|Intel Core Processors三个产品线上提供更快的模型推理速度。根据英特尔的测试,最高可以提速数十倍。
另外这个项目是上海英特尔主导开发的,所以网上有不少中文资料。对于出现的问题,也可以更好的在Github上沟通。
我在这篇文章种将主要演示使用ITREX执行大型语言模型推理,对于希望使用该项目进行微调或是其他用途的用户,可以参考项目首页的相关文档。
https://github.com/intel/intel-extension-for-transformers
在Intel Xeon Scalable系列处理器上快速开始
如果不需要使用Github仓库中的最新版代码,可以直接使用pip安装intel-extension-for-transformers包,这篇文章面向希望执行LLM推理的新人,故不对编译安装intel-extension-for-transformers进行过多赘述。如果需要,请查阅官方文档。
我这里将依然以SakuraLLM大模型为例,使用的版本是0.9.0pre3,基地模型是阿里的千问大模型。目前ITREX支持的模型可以在下面的链接查看
https://github.com/intel/intel-extension-for-transformers/tree/main/intel_extension_for_transformers/llm/runtime/graph#text-generation
本文将展示两种形式运行模型,一种是来自intel-extension-for-transformers仓库的实例代码,通过几行代码就可以执行大型语言模型推理,以及基于我简单修改过的SakuraLLM官方的运行脚本来运行SakuraLLM的API服务。
我推荐使用conda虚拟环境,这样可以避免安装太多pypi包导致的冲突问题,你也可以使用你喜欢的虚拟环境安装这些包。本文将使用conda创建虚拟环境,首先需要创建环境,并激活这个环境。
然后克隆intel-extension-for-transformers仓库到本地(仓库中有依赖文件需要安装),并使用pip命令安装依赖。
ITREX项目中共有两处依赖需要安装,第一个是位于根目录下的requirements.txt,第二个是位于intel_extension_for_transformers/llm/runtime/graph目录下的requirements.txt,这俩依赖都需要安装。
conda create --name ITREX-DEMO python=3.10 #使用conda创建一个叫做ITREX-DEMO的环境,使用python3.10 conda activate ITREX-DEMO #激活该虚拟环境 git clone https://github.com/intel/intel-extension-for-transformers.git #克隆ITREX仓库 cd intel-extension-for-transformers pip install -r requirements.txt #安装根目录的依赖 pip install -r intel_extension_for_transformers/llm/runtime/graph/requirements.txt #安装LLMRuntime的依赖 pip install intel-extension-for-transformers #安装本体 #pip install -v . #(可选)编译安装最新版代码
安装完成后,我们就可以在ITREX-DEMO虚拟环境下执行大型语言模型推理了,首先让我们试一下小玩具,通过几行代码实现快速的基于qwen的llm推理,你只需要复制下面的代码并简单修改。
from transformers import AutoTokenizer, TextStreamer
from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig
model_name = "Qwen/Qwen-7B-Chat" # 改为下载好的模型路径或者huggingface的仓库名
woq_config = WeightOnlyQuantConfig(compute_dtype="bf16", scale_dtype="bf16", weight_dtype="int4") #使用Int4量化
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=woq_config, trust_remote_code=True)
while True:
prompt = input("> ").strip()
if prompt == "quit":
break
prompt = "\n<|im_start|>user\n{}<|im_end|>\n<|im_start|>assistant\n".format(prompt) # prompt template for qwen
inputs = tokenizer([prompt], return_tensors="pt").input_ids
outputs = model.generate(inputs, streamer=streamer, interactive=True, ignore_prompt=True, do_sample=True)
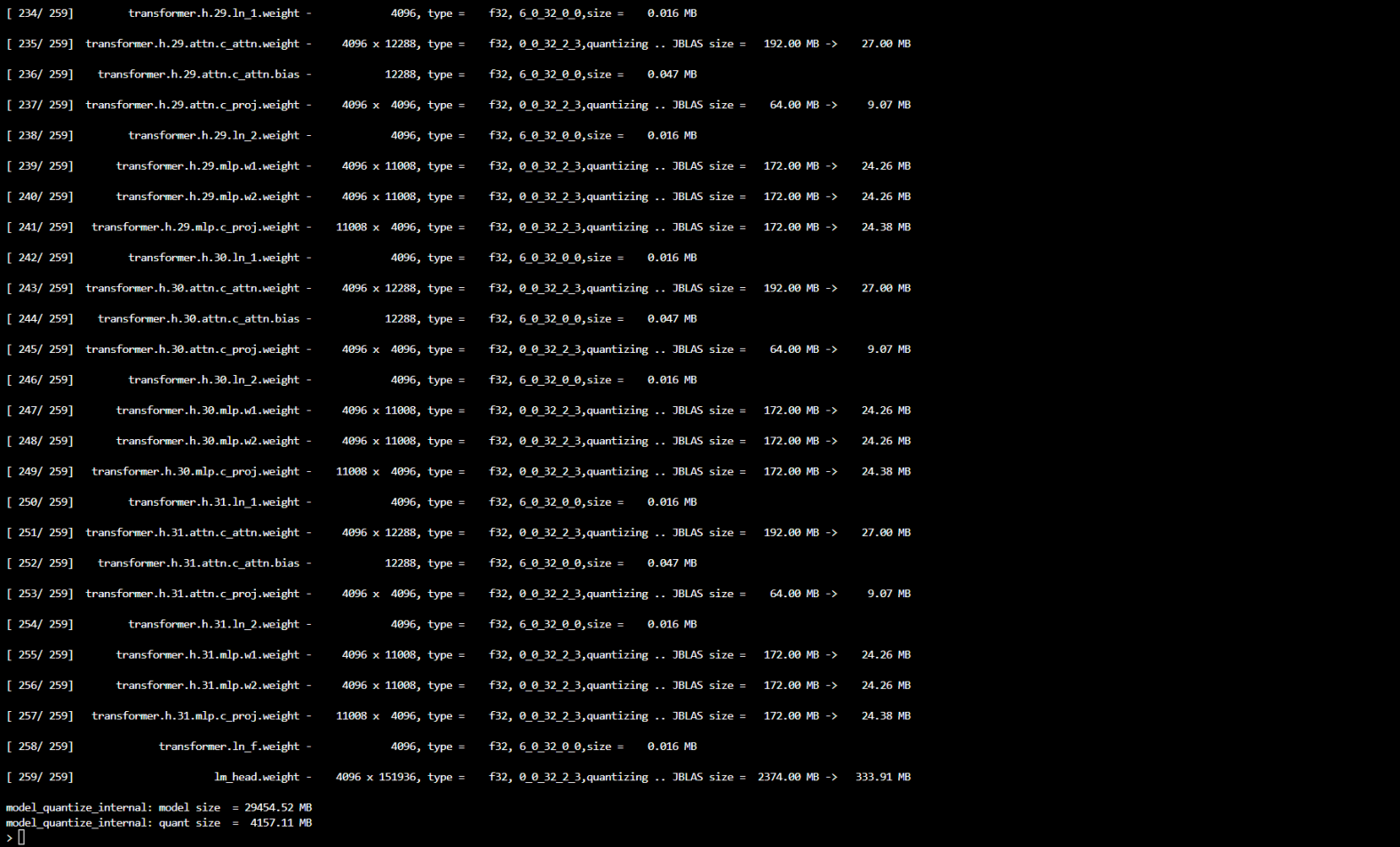
直接执行这段代码就可以看到效果了,如果你填写的是huggingface的仓库名,transformers会自动下载模型,如果你填写的是已经下好的模型路径,transformers会自动加载他。一旦加载成功,ITREX.cpp会首先量化该模型。ITREX.cpp量化的模型会有缓存,下次执行会自动尝试读取量化模型。
※不要再intel-extension-for-transformers项目根目录执行
如图所示即为量化完毕,在命令行中输入prompt就可以开始推理了。
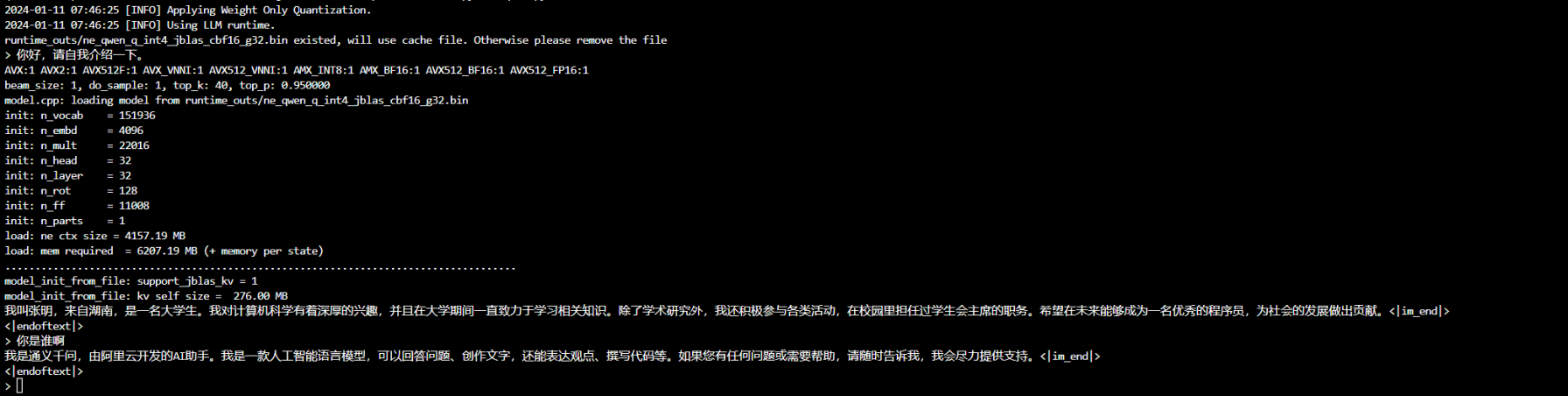
简单尝试一下后,我们可以试一下使用SakuraLLM来翻译文本。SakuraLLM本文不再介绍,您可以访问他们的官方仓库了解更多。博主fork了一份并简单的修改兼容了一下ITREX,仓库链接放在下方。
博主修改版,兼容ITREX.cpp: https://github.com/kunger97/Sakura-13B-Galgame SakuraLLM官方仓库: https://github.com/SakuraLLM/Sakura-13B-Galgame
克隆修改版仓库后,还需要安装一些依赖,主要是给API使用的
git clone https://github.com/kunger97/Sakura-13B-Galgame.git #克隆修改版仓库 cd Sakura-13B-Galgame #进入项目目录 pip install sentencepiece bitsandbytes scipy numpy #安装依赖 pip install -r requirements/server.txt #安装API环境
接下来就可以执行server.py来运行API服务器了,translate_novel.py 和 translate_epub.py这两个翻译脚本也是可用的。根据需要使用即可,关于命令行帮助,你可以通过 -h 来打印出来
我修改过的代码使用如下命令来通过ITREX.cpp执行模型,其中OMP_NUM_THREADS是环境变量推荐加上,当然你不知道怎么填,也可以删掉,直接执行python命令后面的,要注意你可以使用–itrex_dtype来指定量化类型,对于CPU推理我推荐使用Int4这个跑起来速度还行,如果使用其他类型的量化,可能影响速度。
我的代码也支持使用bigdl将模型加载到XPU,未来我会在专门出一个教程。
OMP_NUM_THREADS=<物理核心数> python server.py --no-auth --model_name_or_path ~/Models/Sakura-13B-LNovel-v0_9_0pre3/ --model_version 0.9 --trust_remote_code --itrex_cpp --itrex_dtype int4
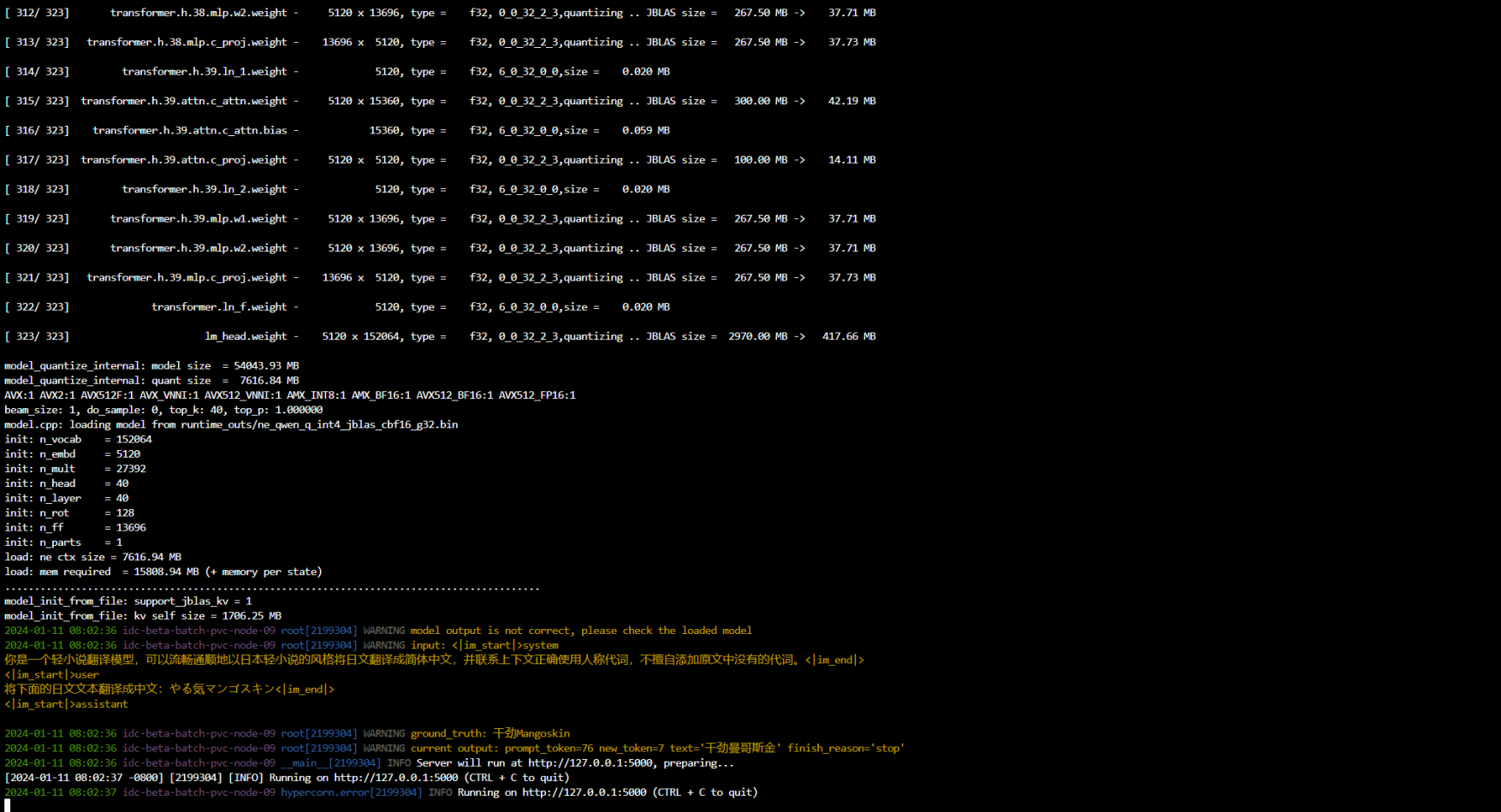
首次加载模型会执行量化,需要多等一会,量化结束后就显示API的地址了。我们可以到轻小说翻译机器人网站去试一下,他们网站支持添加自己的SakuraLLM翻译API进行翻译。添加API是要注意,使用SakuraLLM以及我修改过的仓库时,不要勾选LlamaApi。
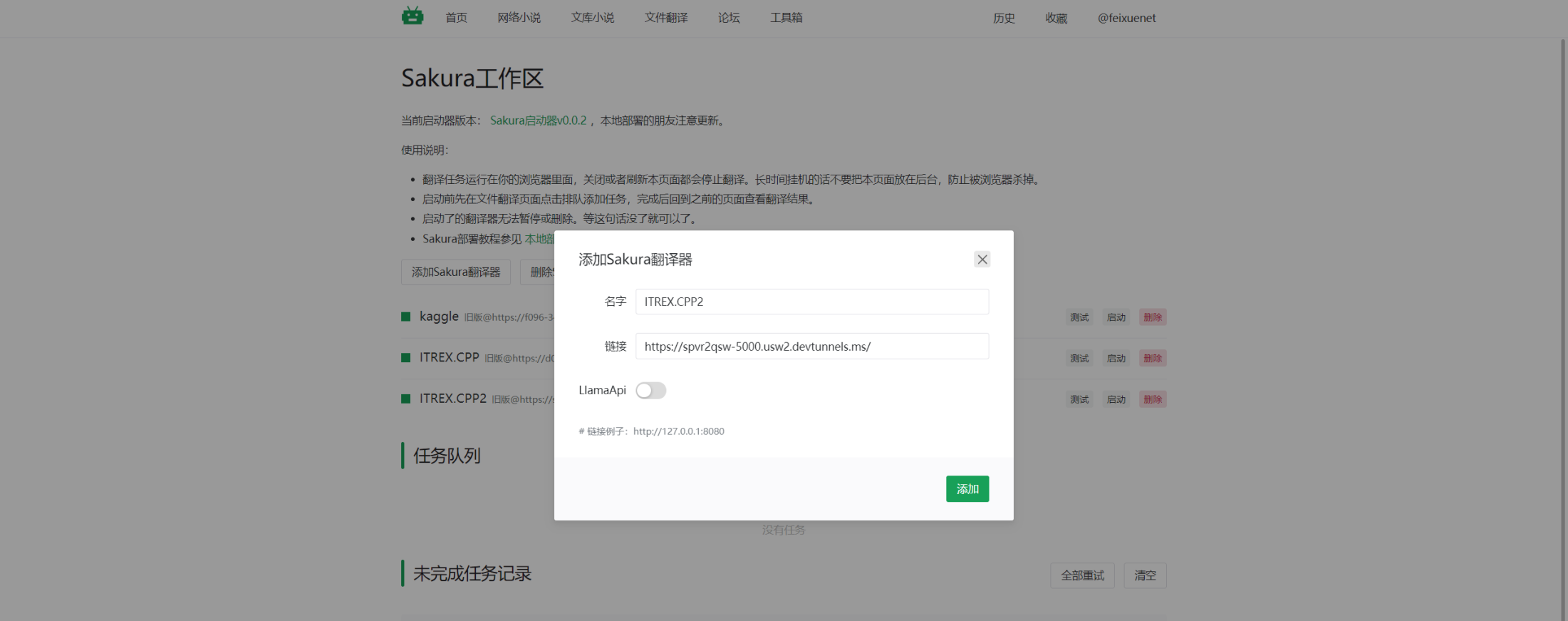
添加完成后点测试看看模型有没有输出,如果有你就可以执行翻译任务试一下了。
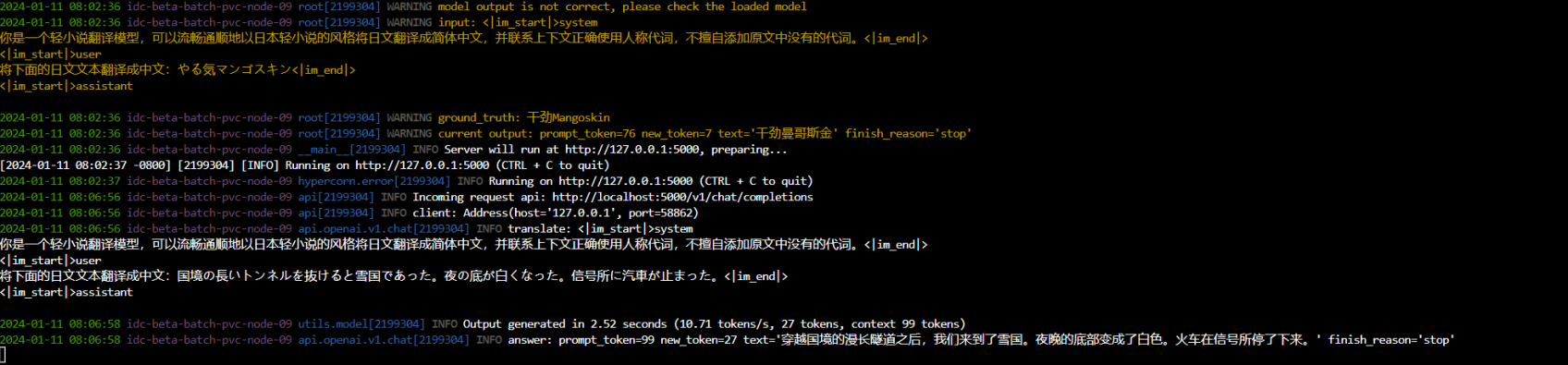
在使用Intel(R) Xeon(R) Platinum 8480+执行Int4量化推理时,大约可以达到13-14tokens/s,这个速度基本堪用了。想要更快的推理速度,那基本上就得用显卡加速了。
头部图片来自PIXIV@のん,作品ID为:115013250
评论(2)